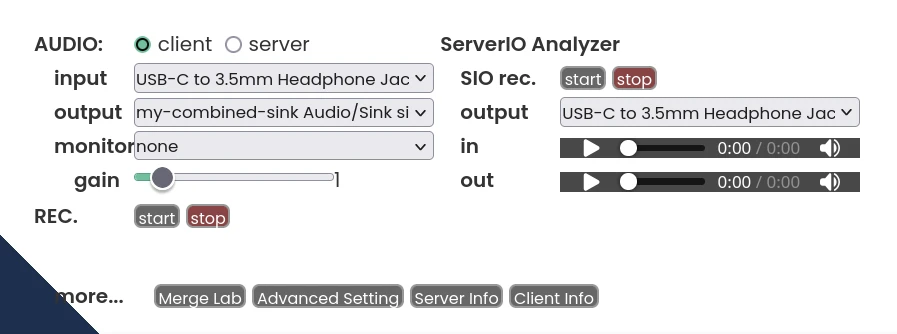
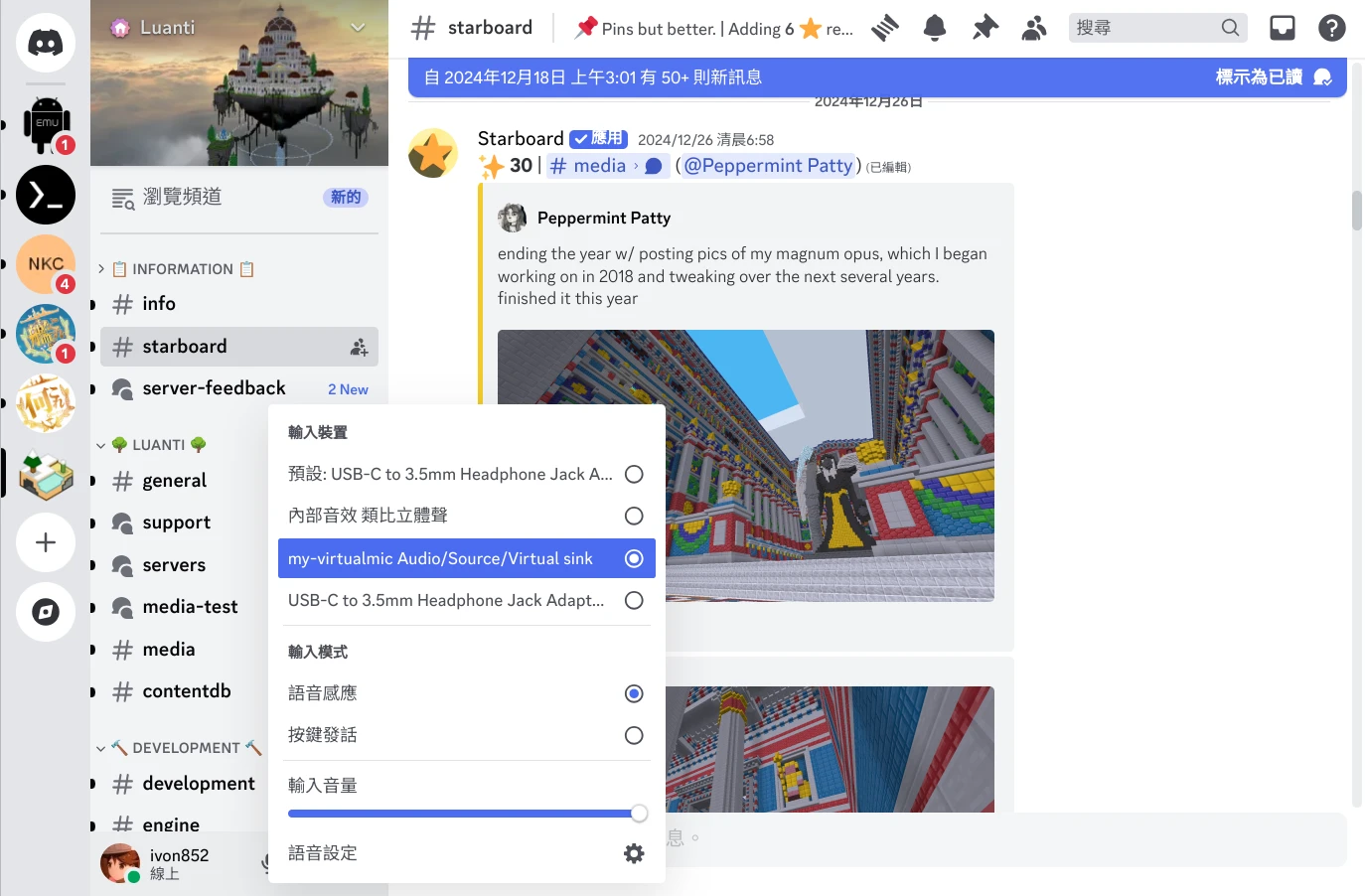
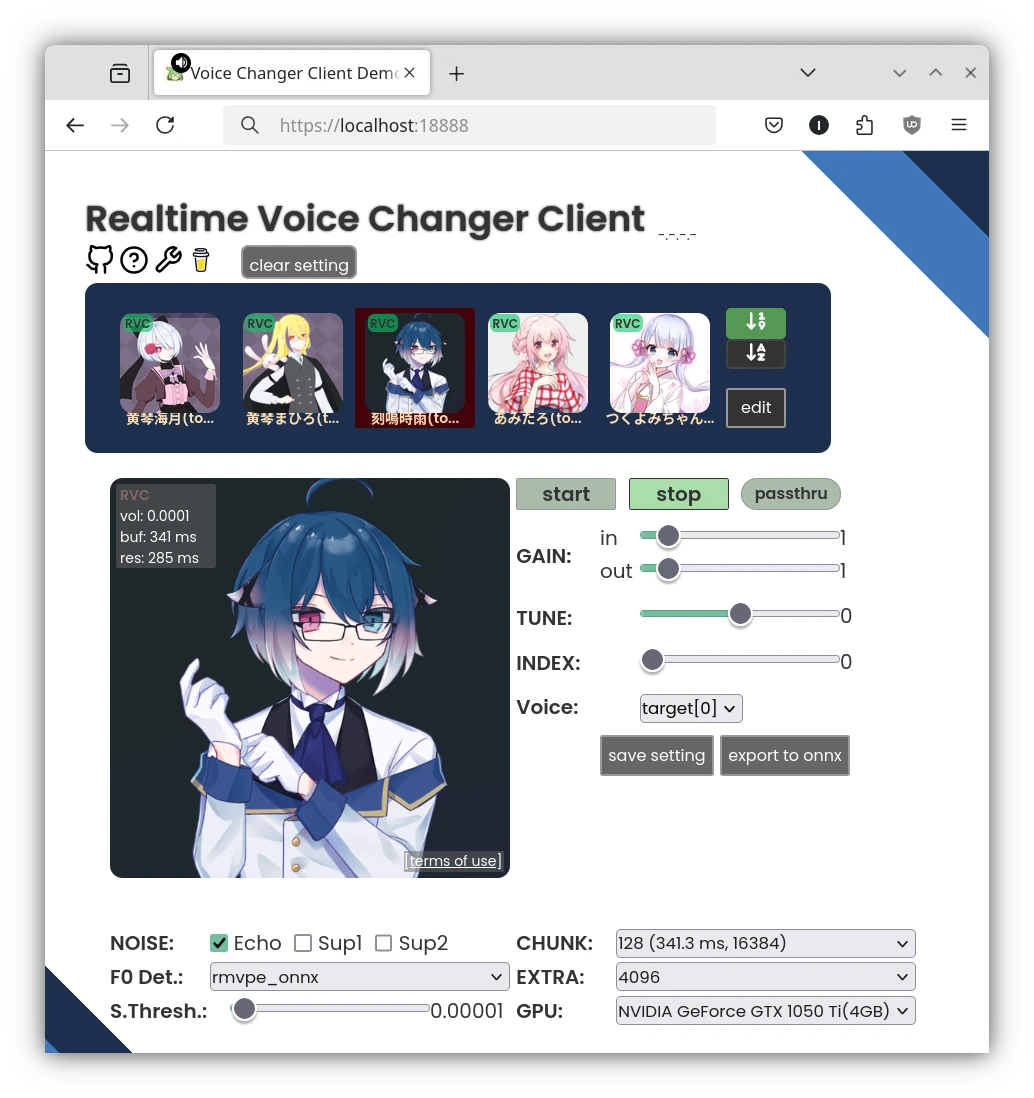
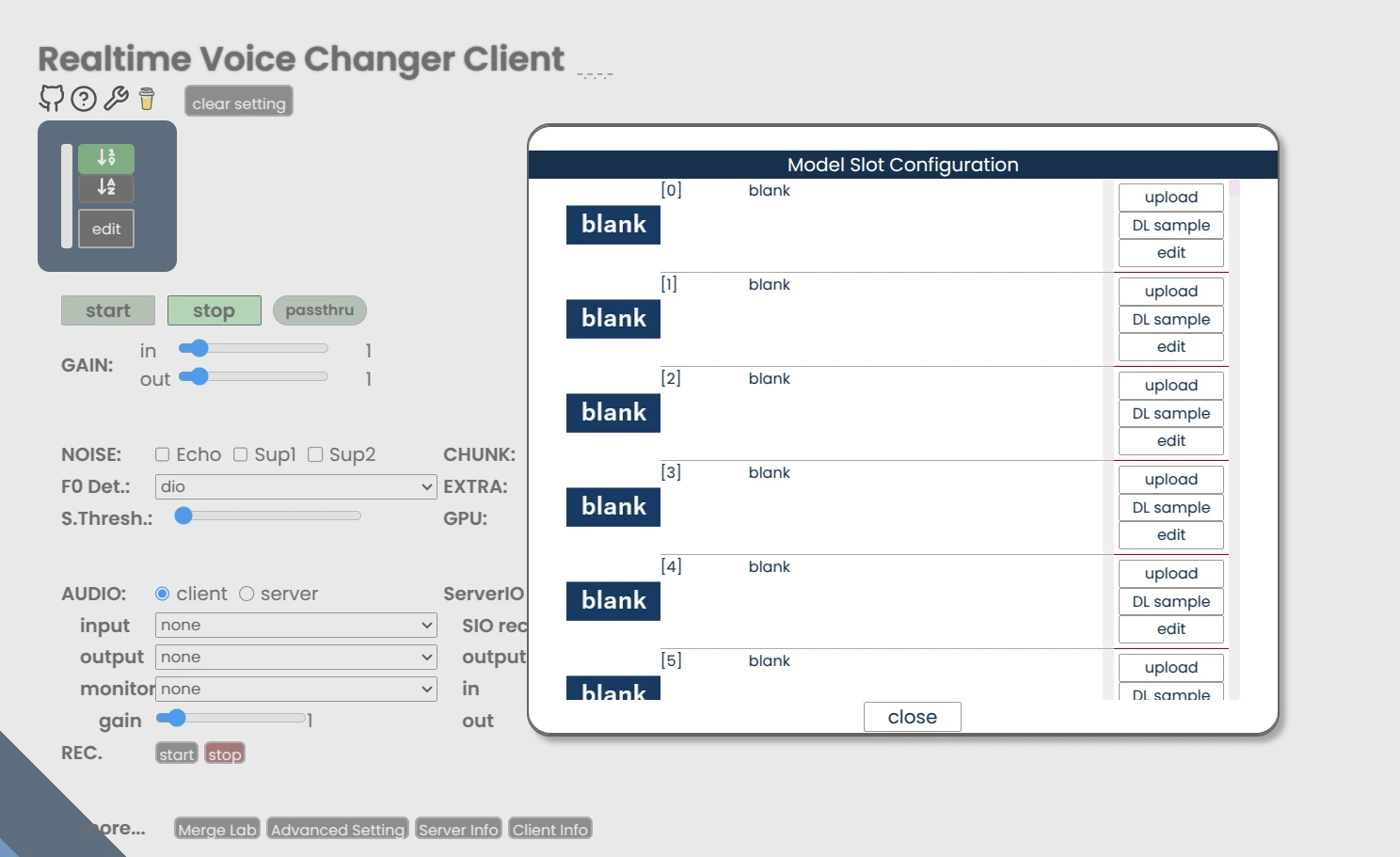
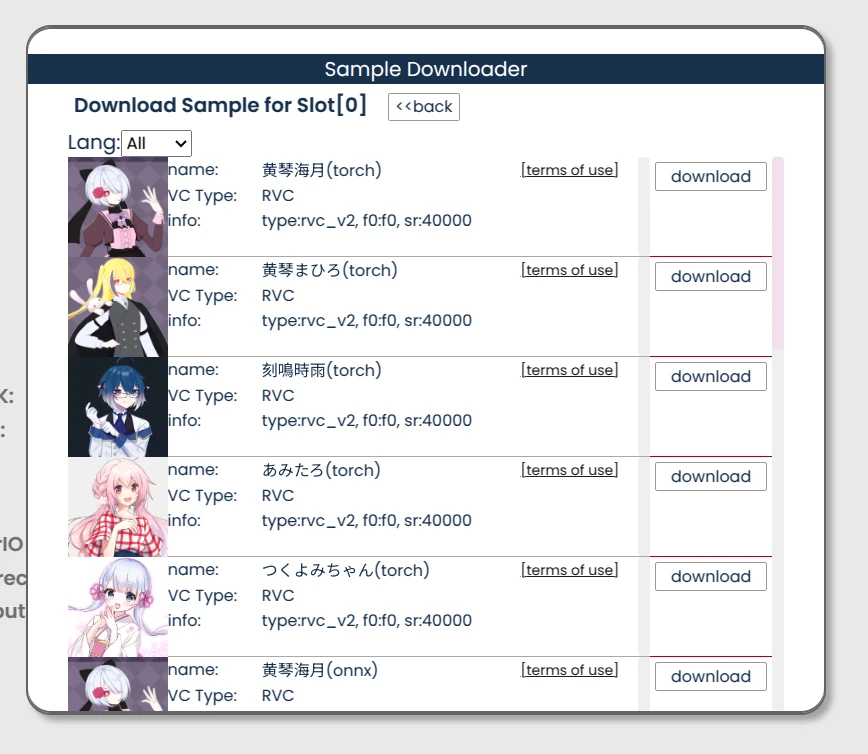
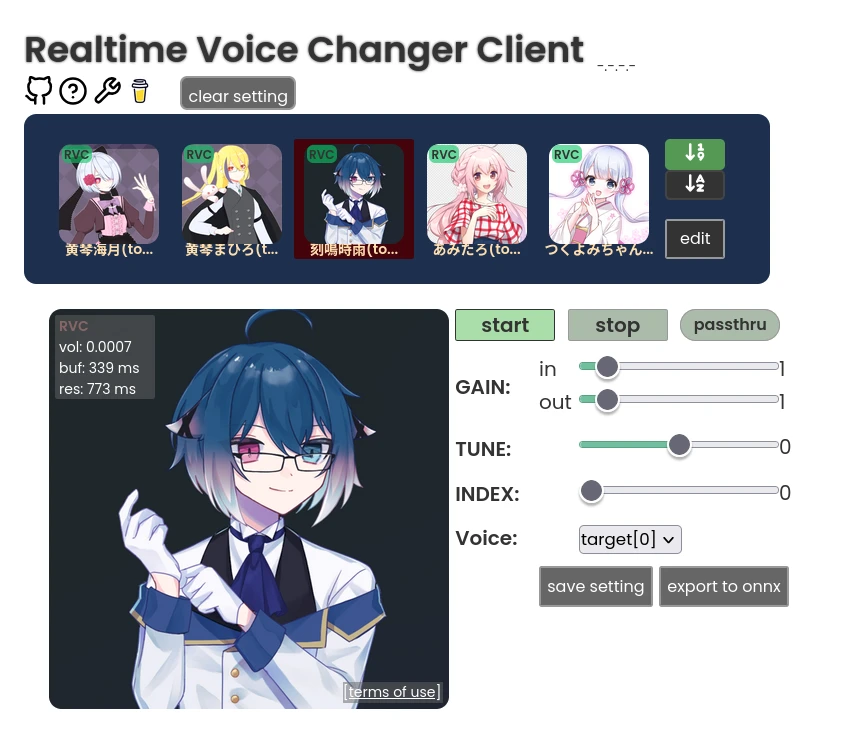
Realtime Voice Changer Client(簡稱VC Client)為一款開源AI即時變聲器,適合在直播或者語音聊天的時候使用,實現即時變聲,讓你用不同的聲音說話。 它整合了RVC、VITS、Beatrice、MMVC、so-vits-svc等多種技術來達成變聲。 這裡Ivon會先分享如何在Linux系統安裝VC Client,解說如何搭配OBS Studio直播軟體使用。 之後分享,如何透過PipeWire的功能,把VC Client變聲後的音訊,當成一個虛擬麥克風,便能在其他通訊軟體,例如Discord裡面使用。 1. VC Client硬體需求 VC Client提供WIndows、macOS、Linux版本。 WIndows和macOS有執行檔可以下載,Linux得用Docker跑。 VC Client支援透過CPU或Nvidia GPU計算。要輸出高品質的音訊,至少需要4GB的VRAM,而且還要即時轉換,老實說這個吃資源有點兇。 這個軟體有一個WebUI,能在區域網路執行,若是覺得本機運算開銷過大,那麼把變聲器的任務放在另一台電腦上跑也是可以。 2. Linux透過Docker安裝VC Client 這是作者推薦的方式,但作者的Docker映像檔已經一年以上沒更新了,導致無法使用RVC以外的新模型。若需要最新功能,請手動設定Python環境。 以Ubuntu為例,先安裝Docker 我要在Docker裡面使用Nvidia CUDA加速,所以得安裝Nvidia Container Toolkit 複製儲存庫 git clone https://github.com/w-okada/voice-changer.git cd voice-changer 執行這個指令稿,拉取映像檔並啟動服務。 ./start_docker.sh 啟動後等待模型下載。 開啟網頁界面:https://localhost:18888。強制使用HTTPS的原因是瀏覽器因素,大多數瀏覽器需要HTTPS才允許存取麥克風,所以這個映像檔會自簽SSL憑證。也可以用https://Linux的區域IP:18888來存取這個網頁界面,讓另一部電腦處理變聲器計算,降低主電腦的負擔。 最上面是人聲列表,按Edit,點選格子,點選DL Sample,下載範本模型。 一個格子只能下載一個模型。這裡的模型主要是RVC,網路上有很多人分享,所以你能上傳新的RVC模型,也可以自行用RVC WebUI訓練一款變聲模型。 設定音訊處理方式。Noise勾選Echo,消除回音。接著,F0 Detect設定rmvpe_onnx,用CPU跑音高辨識模型。最後選取使用GPU計算。 Flash: https://static.ivonblog.com/posts/realtime-voice-changer-client/images/Screenshot_20250302_213122.webp 設定輸入裝置。 點選Audio,勾Client,Input勾選Linux的麥克風裝置。建議使用耳麥或者桌上型麥克風,收音比較清楚,為的是背景不要有太多噪音,免得程式把電腦風扇也當作人聲在講話。 Output勾選揚聲器,或是其他音訊輸出裝置。因為VC Client會輸出音效到揚聲器,導致你會一直聽到自己變聲的音效。覺得太吵的話,就把它輸出到耳機吧。 3. Linux手動設定VC Client的Python環境 執行Python原始碼,存取最新功能。 安裝Anaconda 建立Python 3.10的虛擬環境 conda create -n vcclient-dev python=3.10 conda activate vcclient-dev 複製VC Client儲存庫,安裝依賴 git clone https://github.com/w-okada/voice-changer.git cd voice-changer/server pip install -r requirements.txt 啟動伺服器 python3 MMVCServerSIO.py -p 18888 --https true 4. VC Client變聲操作 點選格子裡面的大頭貼,選取模型,點選Start開始變聲。 對著麥克風講話,應該會聽到變聲效果,聲音會有一點延遲,端看GPU性能。按Passthrough暫時停用變聲。 Tune的數值可以調整講話音高。 要更高品質的合成音,試著把chunk和Extra數值設定高一些,但延遲相應的也會上升。 此外,按Audio下面的REC,能夠錄製講話變聲後的聲音。按下Stop後便會儲存為wav音檔。 5. 搭配OBS Studio使用變聲器 Linux安裝OBS Studio 最簡單的方式是關掉麥克風,讓OBS Studio只捕捉變聲後輸出的聲音。 img]https://static.ivonblog.com/posts/realtime-voice-changer-client/images/Screenshot_20250302_202044.webp[/img] 或者請參考下面方法,新增虛擬麥克風。 6. 於通訊軟體使用變聲器 利用PipeWire製造一個虛擬麥克風,用來接收瀏覽器裡面的VC Client所輸出的變聲音效。這樣通訊軟體裡面才可以使用這個麥克風作為輸入來源。 Ubuntu 24.04以後應該是使用PipeWire當音訊系統了,所以此方法可行。 參考:How to create a new pipewire virtual device that to combines an real input and output into a new input? 利用PipeWire(實則是PulseAudio)的指令,新增虛擬槽位,還有虛擬麥克風 pactl load-module module-null-sink media.class=Audio/Sink sink_name=my-combined-sink channel_map=stereo pactl load-module module-null-sink media.class=Audio/Source/Virtual sink_name=my-virtualmic channel_map=front-left,front-right 安裝Helvum,按照下圖,將瀏覽器的輸出接到虛擬槽位,虛擬槽位再接到虛擬麥克風。 回到VC Client網頁界面,將output設定為虛擬槽位。這樣的話,變聲所輸出的音訊便會全部導向虛擬麥克風了。 開啟通訊軟體,例如Discord,選取虛擬麥克風,應該就只會出現變聲後的聲音。

 img]https://static.ivonblog.com/posts/realtime-voice-changer-client/images/Screenshot_20250302_202044.webp[/img]
img]https://static.ivonblog.com/posts/realtime-voice-changer-client/images/Screenshot_20250302_202044.webp[/img]